
Una de las cosas que más me gusta de “evangelizar” sobre el Cloud es la posibilidad de charlar con personas de diferente posición con respecto a la IT dentro de una organización. Por ejemplo, las dudas, cuestiones e inquietudes varían terriblemente si estamos hablando con un:
- Desarrollador de aplicaciones (en sus distintos grados de “seniority” y al margen de la tecnología en que desarrolle)
- Administradores de sistemas y en general personal vinculado con la operación de los sistemas
- CxO
- Directivos, mandos intermedios y en general lo que podíamos denominar consumidores finales de la tecnología, sin ser ellos en muchos casos participes de su desarrollo
evidentemente con un grupo tan dispar, los intereses, motivaciones y consideraciones de cada uno de estos grupos lo será también y saldrá a la luz por ejemplo a la hora de desarrollar o adaptar una aplicación para la Cloud.
Dejando al margen consideraciones relativas a usabilidad y funcionalidad (asumiremos que seremos capaces de desarrollar una aplicación usable y que funcione) e incluso de tecnología (nos abstraeremos de decisiones vinculadas a la tecnología tales como la elección del lenguaje de programación), ¿qué deberíamos tener en cuenta a la hora de tener una aplicación CloudReady?
Nota: las ilustraciones he intentado que sean agnosticas por lo que serían extrapolables a cualquier proveedor que ofreciese las mismas funcionalidades.
Principios básicos del Cloud:
El cloud cobra sentido en el momento en que nos damos cuenta de que podemos tener acceso a un completo stack tecnológico, pagando solo por aquellas características que usamos y liberándonos del coste asociado a poseer la infraestructura necesaria para disfrutar de esos servicios, por ejemplo:
- Dispondremos del múltiples regiones distribuidas por el mundo (ideal para recuperación de desastre o para dar servicio a clientes en distintas zonas geográficas)
- Algunos proveedores operan múltiples datacenter en una misma región (aún más tolerancia a fallos)
- Flexibilidad (podemos crecer y decrecer conforme lo necesitemos, pagando solo por lo que usemos y sin lastrarnos con costes de propiedad)
- Escalabilidad (podemos crecer hasta el “infinito” si lo necesitamos
- Facilidad ( el operador de Cloud ya ha desarrollado numerosas funcionalidades que pueden hacernos la vida más fácil, serverless, PaaS, etc.)
- y un largo etc.
entonces, ¿qué deberíamos tener en cuenta a la hora de tener una aplicación CloudReady?
Principios de una aplicación Cloud Ready:
Una aplicación Cloud Ready de “libro” es aquella que nos va a permitir sacar el máximo rendimiento a todo el stack tecnológico que tenemos a nuestra disposición.
Escalabilidad el reto del Stateless:
Bien, como ya todos sabéis las escalabilidad puede ser vertical (incrementando los recursos asociados a un servidor) u horizontal (incrementando el número de recursos asociados a un pool de trabajo), desde el punto de vista de escalado vertical debemos tener en cuenta que la tecnología que usemos no establezca limites demasiado bajos que por ejemplo condicionen el nº máximo de vCPUs o de memoria asignadas las máquinas.
¿Qué pasa con el escalado horizontal?, la respuesta rápida es que es muy sencillo de hacer en el cloud, replicamos máquinas virtuales y colocamos un balanceador por delante que además detecte si un servidor a caído o no. Ya está, ¿fácil verdad?,
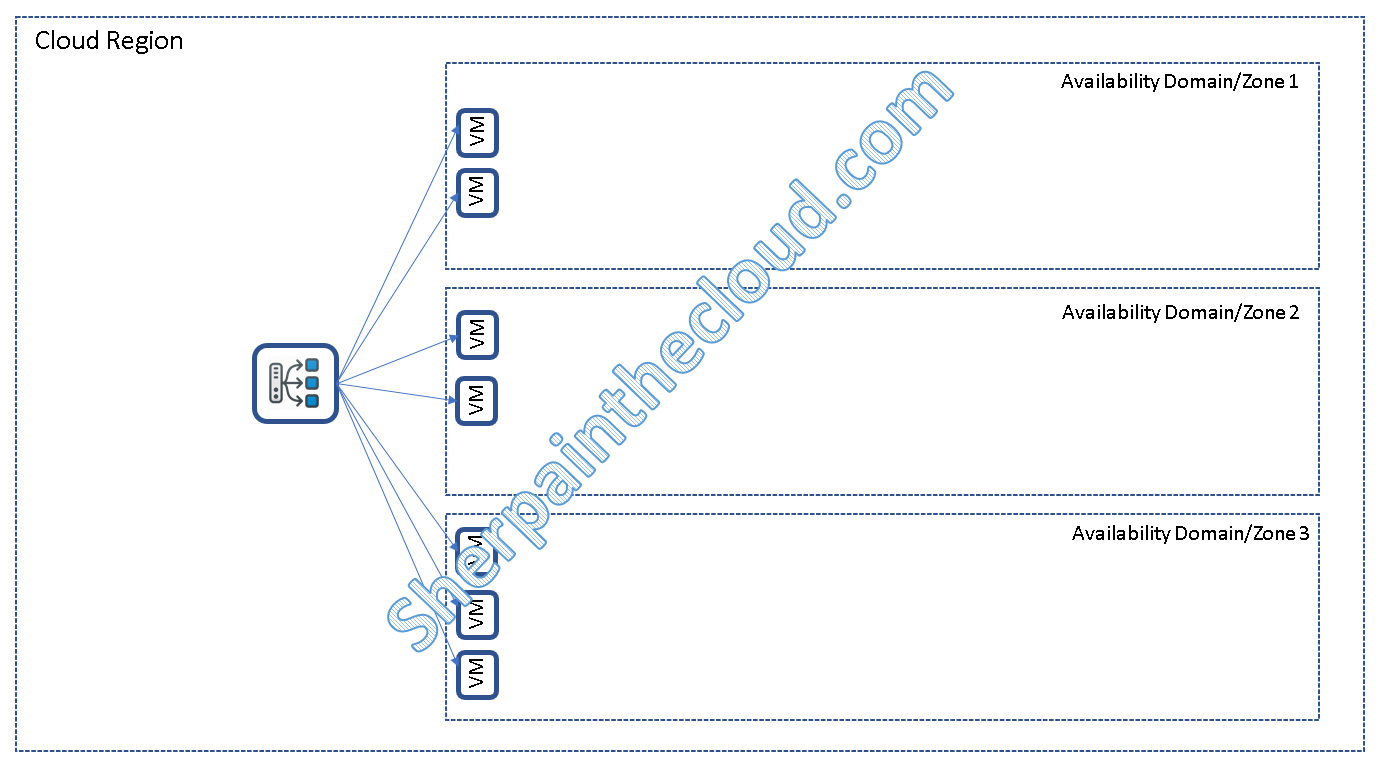
pero… y que ocurre con las sesiones, ¿da igual que nos atienda un servidor un otro?. Si la respuesta es no, significa que nuestra aplicación no es stateless.
La solución rápida pasa nuevamente por hacer que una conexión vaya siempre al mismo servidor, lo que llamamos conexión persistente o Sticky. Este tipo de conexiones puede originar que nuestro balanceo de carga no sea perfectamente simétrico, originando otro tipo de problemas.
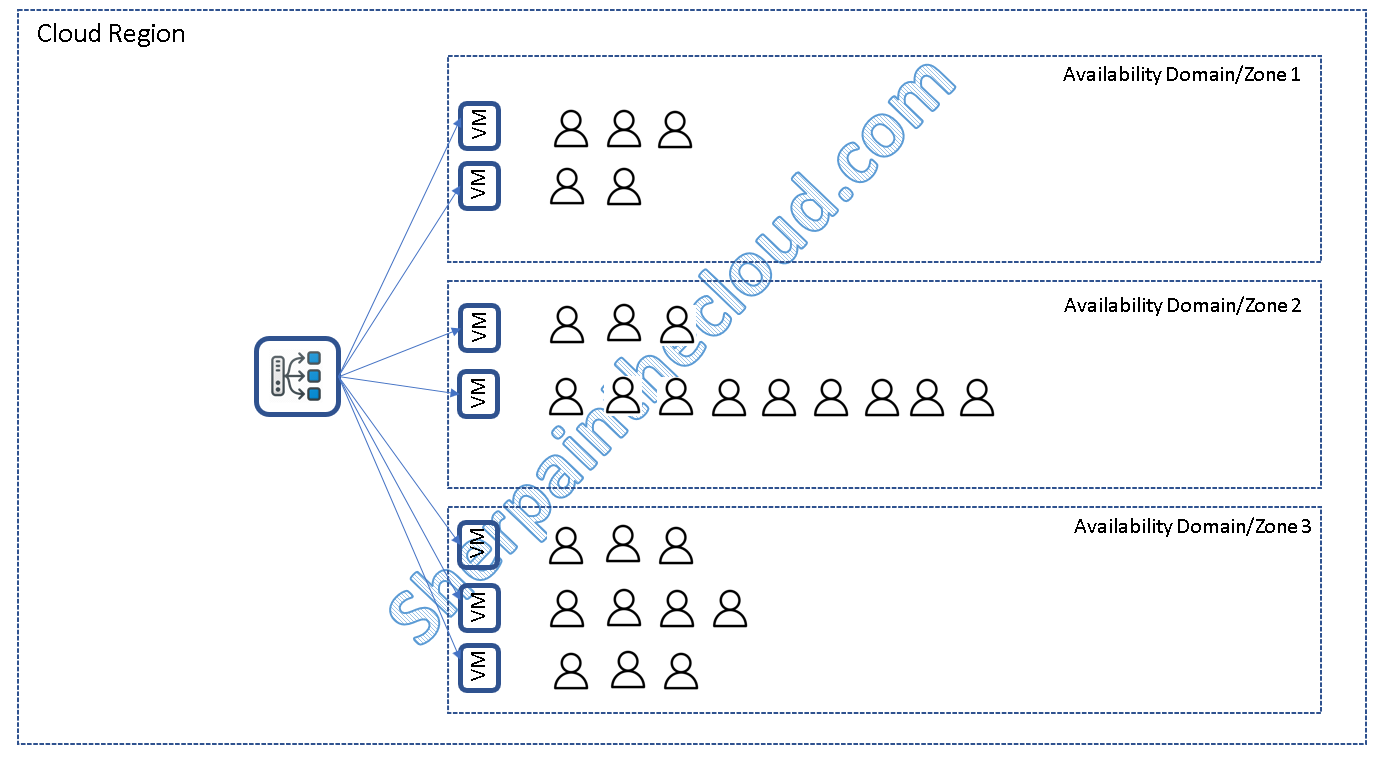
Stateless Load Balancing
La solución elegante y Cloud Ready sería hacer que nuestra aplicación fuera stateless (o al menos que el estado de la sesión no residiese en la propia conexión), de esta manera cualquier servidor podría atender cualquier petición y sería mucho más fácil conseguir un balanceo óptimo, también ante fallos. (Los colores indican peticiones de un mismo usuario, para ilustrar que las puede atender cualquier servidor)
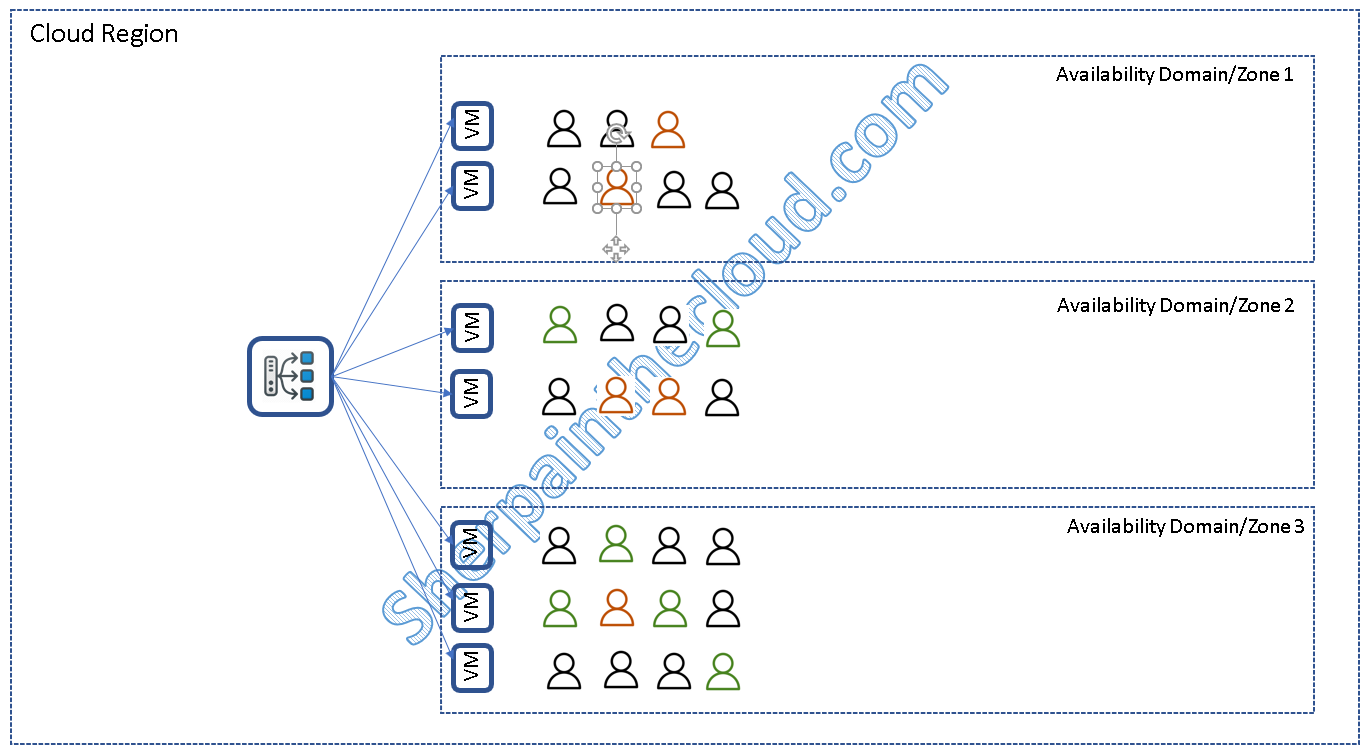
Ahora mucho mejor, ¿verdad?
Tolerancia a fallos. because problems happen!!
Tarde o temprano nuestra aplicación fallará por uno u otro motivo y lo resiliente que será a estos fallos, dependerá en gran medida de su diseño.
Los balanceadores de carga por ejemplo, nos permitirán "sacar" a un nodo con problemas y mandar a los clientes a nodos "healthy", si además nuestra aplicación es stateless, ni siquiera será necesario iniciar de nuevo la sesión.
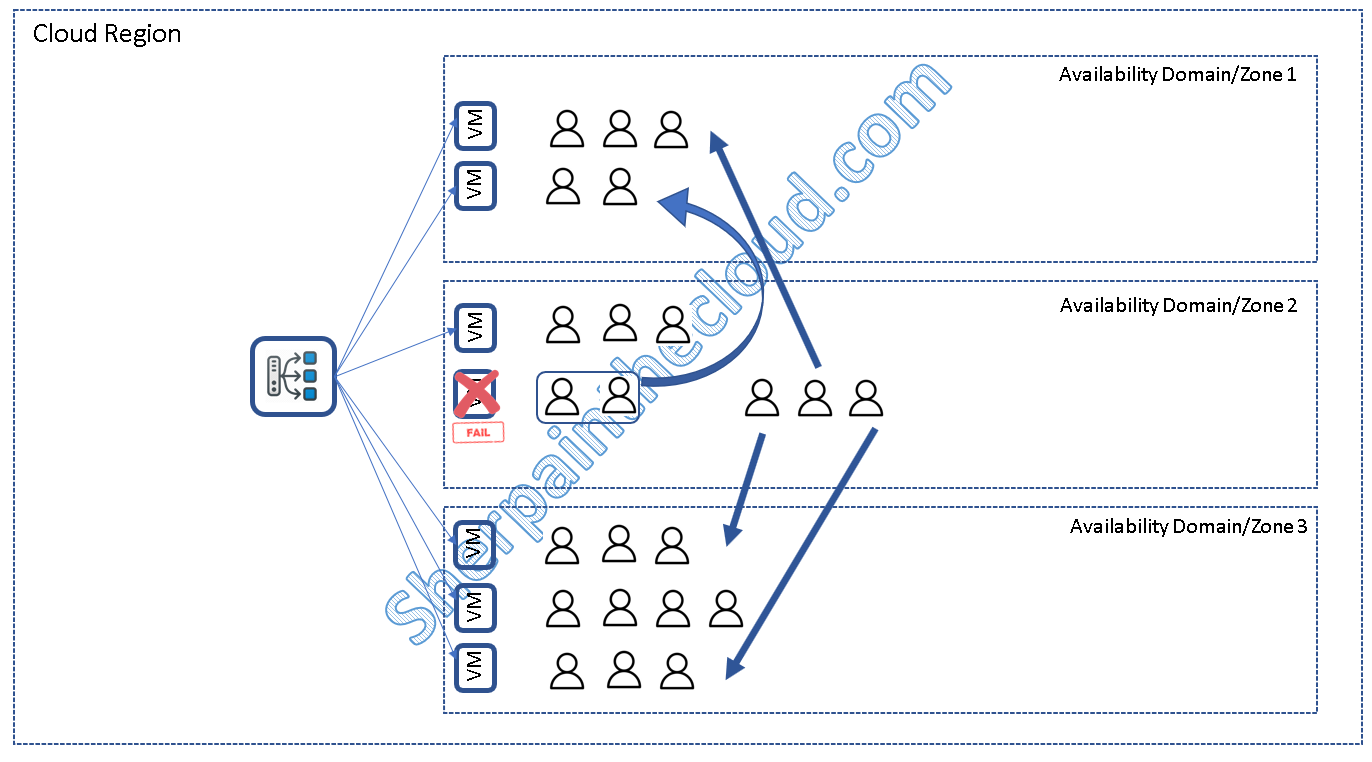
Tolerancia a fallos el reto de la persistencia del dato:
Aunque el uso de balanceadores ya aporta cierta tolerancia al fallo, la realidad es que este tipo de dispositivos están pensados para situarse delante de servidores web y de aplicación, pero existen otros muchos tipos de servicio que no podrían beneficiarse (al menos en primera instancia de esta funcionalidad).
Conseguir la persistencia del dato a nivel de fichero puede ser tan sencillo como hacer uso de funcionalidades como el ObjectStorage o similar, que de manera nativa van a realizar replicación del dato entre distintas Zonas de disponibilidad, garantizando así su supervivencia.
El almacenamiento tipo ObjectStorage, suele permitir servir contenido estático, por lo que incluso podríamos usarlo para servir este contenido desde fuera de nuestra aplicación, de esta manera aliviamos la carga de nuestros servidores y ganamos rendimiento, dirigiendo este tráfico a una infraestrucutura de alto rendimiento y resiliencia.
genial tenemos nuestros datos a salvo en un almacenamiento distribuido y de alto rendimiento, pero ¿Qué pasa por ejemplo con las bases de datos?
Bien, las bases de datos son probablemente el caso más complejo a la hora de conseguir alta disponibilidad y balanceo de carga, ¿por qué?. Bien, cuando hablamos de BBDD, solemos estar pensando en BBDD relaciones, donde es importante manterner la integridad del dato. Mantener la integridad del dato no es secillo cuando aumentamos el nº de actores (nodos) sobre todo si queremos que estos nodos sean un activo /activo con capacidades de lectura y escritura. Cada fabricante aborda estos problemas de una manera diferente y las limitaciones de uno u otro producto dependen de las características del mismo.
En general podemo pensar en las siguientes configuraciones tipo:
- Activo/Pasivo => Es la configuración más secillo y podemos por ejemplo ubicar los nodos en distintas AZ/AD
- Activo/Activo (pero este último solo en lectura) => Este despliegue se diferencia del anterior en que el nodo Pasivo, deja de serlo y puede ejecutar consultas de lectura (no escritura)
- Activo/Activo=> Ambos nodos son capacdes de leer y escribir y por supuesto sincronizarse, garantizando la integridad del dato.
La opción más fácil de implementar es un Activo / Pasivo, este tipo de configuración suele ser la primera que soporta cualquier BBDD.
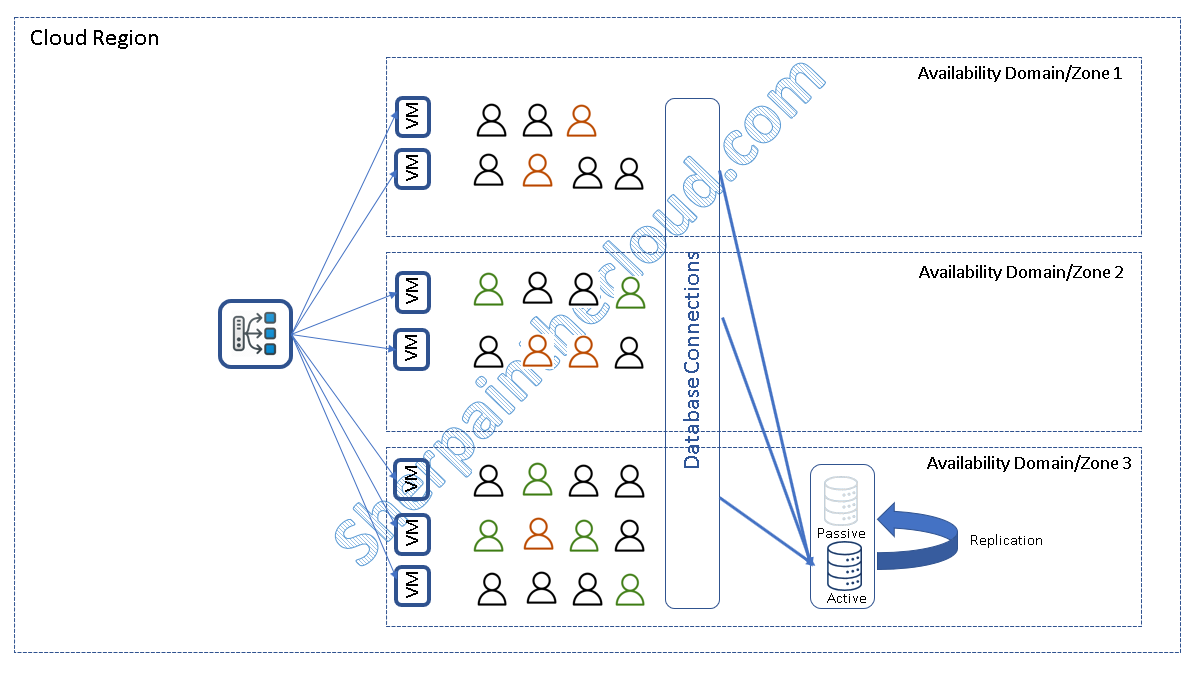
A partir de aquí tenemos n permutaciones :-)
Activo/Pasivo con el pasivo en otra AZ/AD
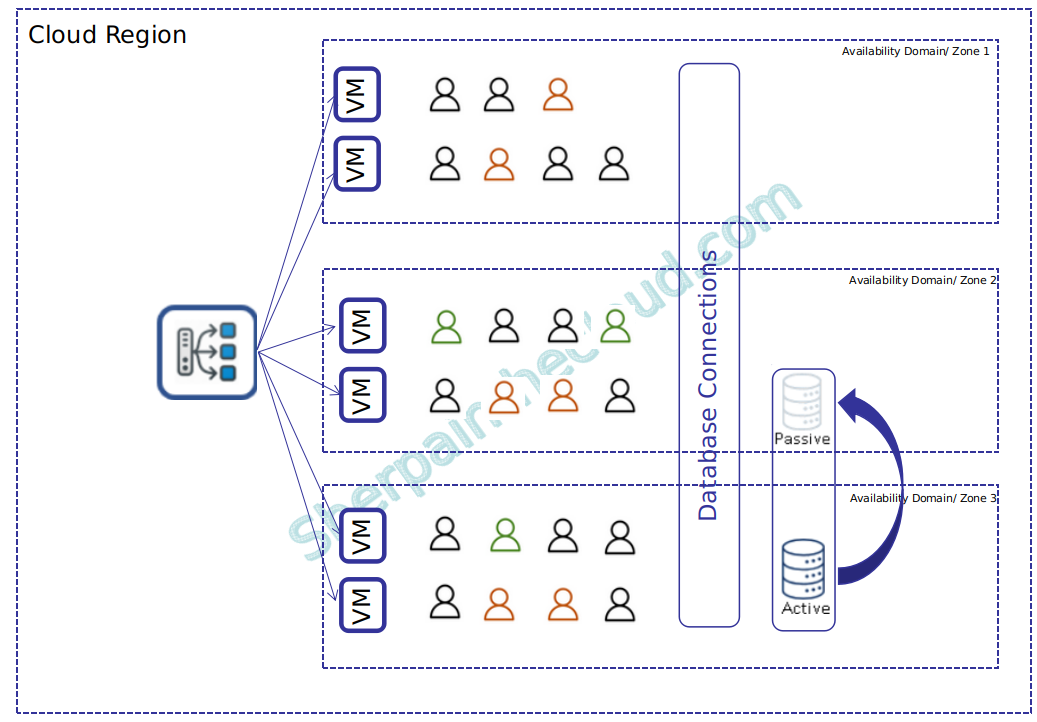
Activo/Activo (recordad que el nodo Activo, no necesariamente tiene que soportar toda la operativa de la BBDD, puede usarse o soportar solo para lecturas.
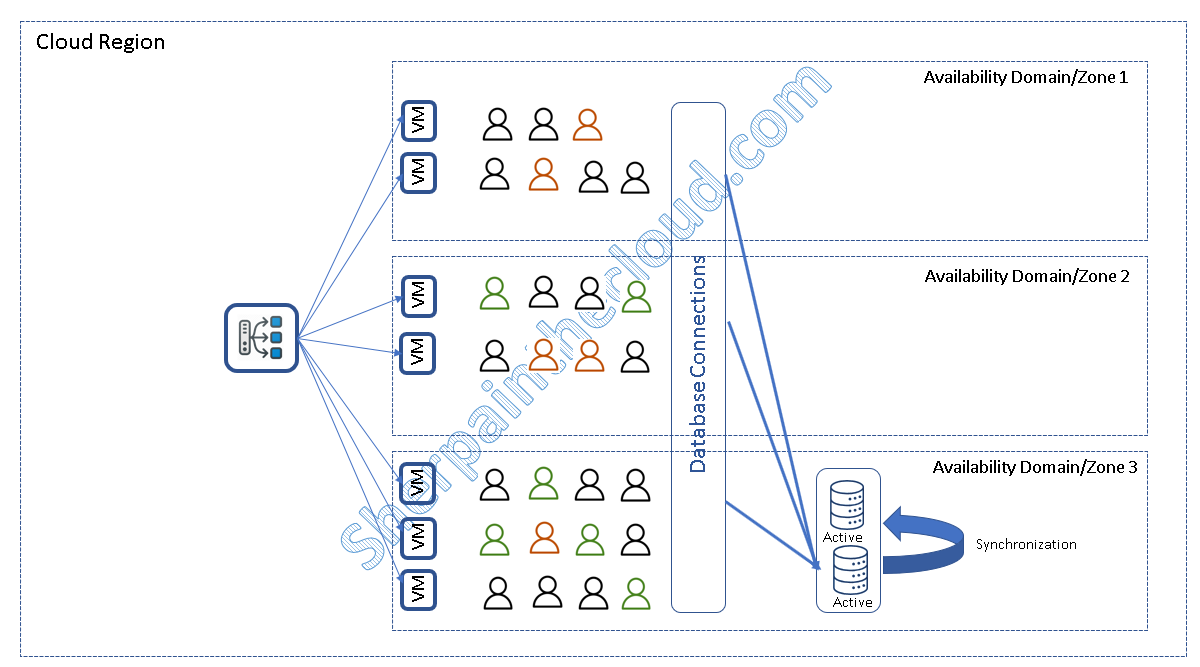
y finalmente la configuración con más disponibilidad a fallos, pero tambien la más compleja de conseguir
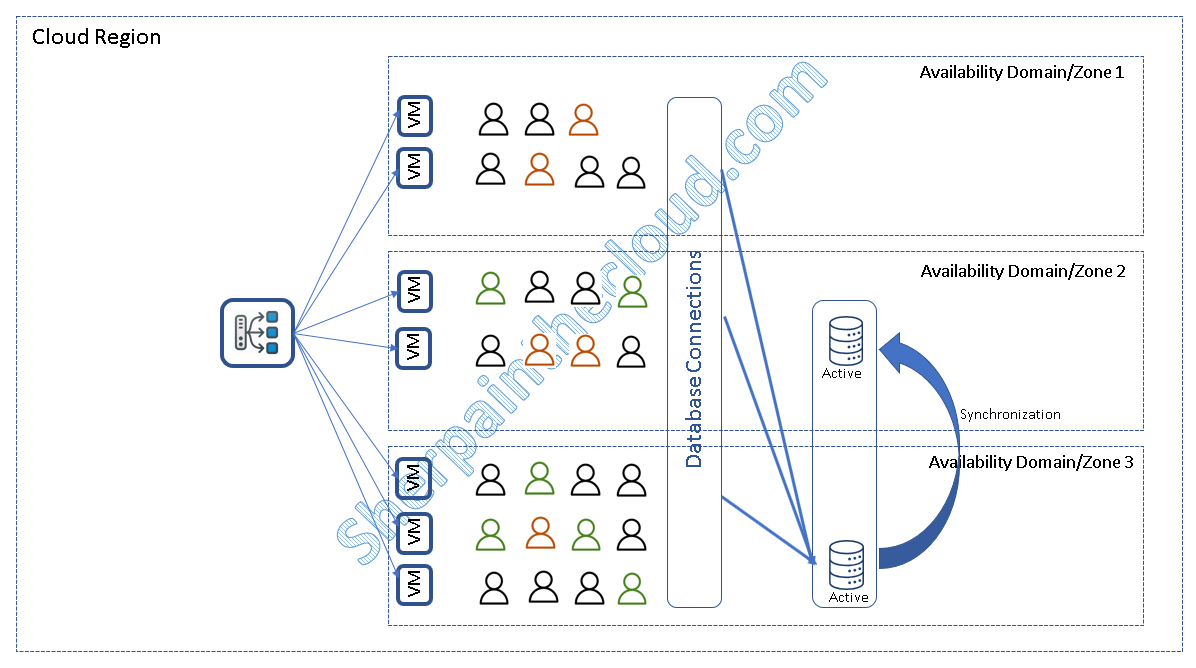
Es importante que tengáis en cuenta aquellas limitaciones propias de la tecnología de BBDD que uséis y del proveedor que elijáis, por ejemplo:
- Si queréis un modelo Activo / Pasivo, ¿necesitáis garantizar la replicación síncrona?
- Si necesitáis replicación síncrona, ¿garantiza vuestro proveedor las latencias mínimas necesarias para no tener problemas?
- ¿Esta certificado vuestro proveedor de cloud para la funcionalidad que queréis usar?
En próximas entradas profundizaremos un poco más en las características que debe reunir nuestra aplicación para ser Cloud Ready.
Espero os haya resultado de interés y utilidad y nos leemos en los siguientes posts.